Background
In this post, I will give a real demo application to show how to do service registration and discovery in Cloud-Native microservice architecture based on Consul and Docker. And the service is developed in Golang language.
It will cover the following technical points:
- Integrate Consul with Golang application for service registration
- Integrate Consul with Golang application for service discovery
- Configure and Run the microservices with Docker(docker-compose)
As you can see, this post will cover several critical concepts and interesting tools. I will do a quick and brief introduction of them.
Cloud-Native: this is another buzzword in the software industry. One of the key attributes of Cloud-Native application is
containerized. To be considered cloud native, an application must beinfrastructure agnosticand use containers. Containers provide applications the ability to run as a stand-alone environment able to move in and out of the cloud and have no dependencies on any certain cloud provider.Service Registration and Service Discovery: in the microservices application, each service needs to call other services. In order to make a request, your service needs to know the network address of a service instance. In a cloud-based microservices application, the network location is dynamically assigned. So your application needs a service discovery mechanism. On the other hand, the service registry acts as a database storing the available service instances.
Consul: Consul is the tool we used in this demo application for service registry and discovery. Consul is a member in
CNCF(Cloud Native Computing Foundation). I will try to write a post to analyze its source code in the future.Docker-compose: is a tool to run multi-container applications on Docker. It allows different containers can communicate with each other. In this post, I will show you how to use it as well.
All the code and config file can be found in this github repo, please checkout the service-discovery branch for this post’s demo.
Service registry and discovery demo
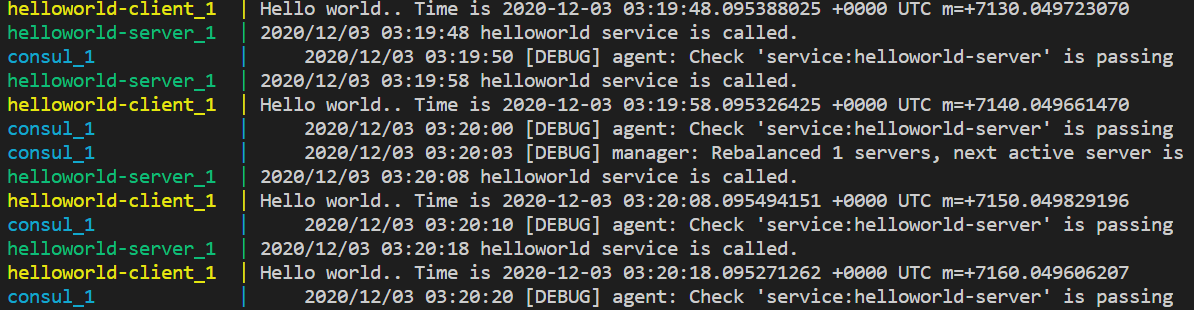
To explain service registry and discovery, I will run a simple helloworld server and a client which keeps sending requests to the server every 10 seconds. The demo helloworld server will register itself in Consul, and this process is just service registry. On the other side, before the client sends a request to the server, it will first send a request to Consul and find the address of the server. This process is just service discovery. OK, let’s show some code.
1 | package main |
server.go
The above server.go file contains many codes, but most of them are easy, and just for setting up the server and handling the request.
The interesting part is inside function serviceRegistryWithConsul. Consul provides APIs to register service by configuring the necessary information. For now, we can focus on two fields, the first one is ID which is unique for each service and we also use it for search the target service in the discovery process. The second one is Check, which means health check. Consul provides this helpful functionality. In the real microservices application, each service may have multiple instances to handle the increased requests when the concurrency is high, this is called scalability. But some instances may go down or throw exceptions, in service discovery we want to filter these instances out. Health check in Consul is just for this purpose. I will show you how to do that in the next post.
1 | package main |
client.go
Similarly, in the client.go file, the only key part is serviceDiscoveryWithConsul function. Based on the Consul APIs, we can find out all the services. With the target service id (in this demo is helloworld-server) which is set in the registration part, we can easily find out the address.
The above parts show how to do the service registry and discovery in a completed demo. It makes use of Consul APIs a lot, I didn’t give too many explanations on that, since you can find out more detailed information in the document.
In the next section, I will show you how to run this demo application in a Cloud-Native way based on Docker and Docker-compose.
Containerization
First let’s create Dockerfile for the server as following:
1 | FROM golang:1.14.1-alpine |
Dockerfile for server.go
This part is straightforward, if you don’t understand some of the commands used here please check the Docker’s manual.
I will not show the Dockerfile for the client any more, since it’s nearly the same as the above one. But you can find it in this github repo.
Now we have both server and client running in containers. We need add the Consul into this application as well, and connect these 3 containers together. We do this with Docker-compose.
Docker-compose is driven by the yml file. In our case, it goes as following:
1 | version: '2' |
There are several points need to mention about docker-compose usages:
- networks: we define a network called
my-net, and use it in all of the 3 services to make them can talk with each other. - environment: we can set up the environment variable in this part. In our case, both server and client need to send requests to Consul for registry and discovery, right? You can check the server and client file, we didn’t set the Consul address explicitly. Since Consul do it in an implicit way, it will get the value from the environment variable named
CONSUL_HTTP_ADDR. We set it up withCONSUL_HTTP_ADDR=consul:8500. - docker-compose up: this is the command all you need to launch the application. Another helpful command is
docker-compose buildwhich is used to build the image defined in the yml file. Of course,docker-compose downcan stop the containers when you want to leave the application.
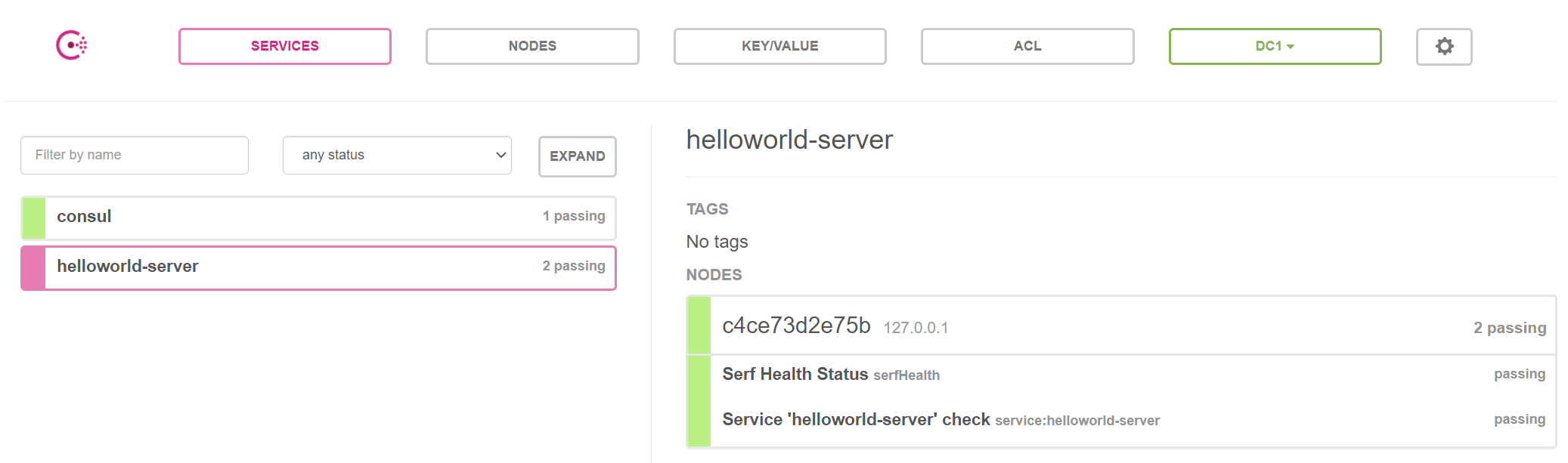
Everything is setted up, you can verify the result both in the terminal and Consul UI as following: